问题描述
最近业务遇到一个问题,在不同Android机型上,设置了cssfont-weight:600;会出现表现不一致的情况。

问题分析
这个问题的原因比较明确,业务css的用法是符合W3C规范的,根本原因是字体库的部分字重缺失,以下是W3C对font weight标准规范的一些参考资料。
相关资料
font weight取值
<font-weight-absolute> = [normal | bold | <number [1,1000]>]Each number indicates a weight that is at least as dark as its predecessor. Only values greater than or equal to 1, and less than or equal to 1000, are valid, and all other values are invalid. Numeric values typically correspond to the commonly used weight names below.
- 100 - Thin
- 200 - Extra Light (Ultra Light)
- 300 - Light
- 400 - Normal
- 500 - Medium
- 600 - Semi Bold (Demi Bold)
- 700 - Bold
- 800 - Extra Bold (Ultra Bold)
- 900 - Black (Heavy)
font weight缺失
W3C对字重缺失也做了详细的解释
2.2.2. Missing weights
Quite often there are only a few weights available for a particular font family. When a weight is specified for which no face exists, a face with a nearby weight is used. In general, bold weights map to faces with heavier weights and light weights map to faces with lighter weights. (See the § 5 Font Matching Algorithm for a precise definition.)

回退机制
这里值得注意的是对于字重缺失,浏览器会有一个回退机制(即自动匹配临近字重的机制)。
- 如果指定的权重值在 400和 500之间(包括400和500):
- 按升序查找指定值与500之间的可用权重;
- 如果未找到匹配项,按降序查找小于指定值的可用权重;
- 如果未找到匹配项,按升序查找大于500的可用权重。
- 如果指定值小于400,按降序查找小于指定值的可用权重。如果未找到匹配项,按升序查找大于指定值的可用权重(先尽可能的小,再尽可能的大)。
- 如果指定值大于500,按升序查找大于指定值的可用权重。如果未找到匹配项,按降序查找小于指定值的可用权重(先尽可能的大,再尽可能的小)。
以上策略意味着,如果一个字体只有 normal 和 bold 两种粗细值选择,指定粗细值为 100-500 时,实际渲染时将使用 normal,指定粗细值为 501-900 时,实际渲染时将使用 bold。
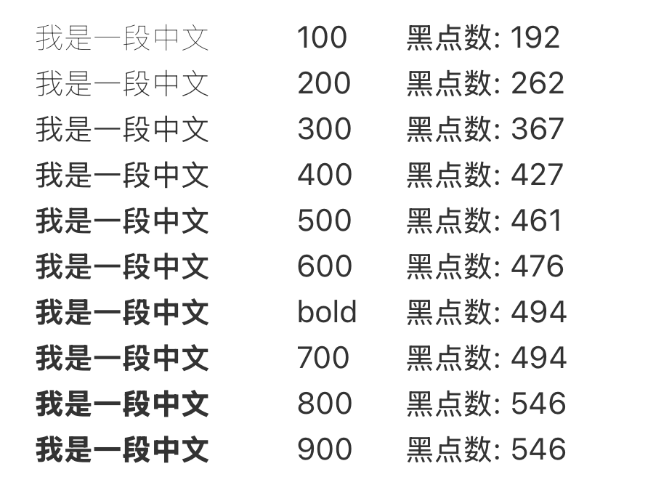
虽然W3C给出了回退机制的规范,但经实测,发现有一些手机并没有严格按照规范实现,所以这个机制并不可靠。
比如下面这台ROG手机,weight 600缺失,符合规则3,应该升序为700;但事实上它和500的表现一样,是降序匹配,这显然与W3C的规则不符。
UserAgent
Mozilla/5.0 (Linux; Android 10; K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Mobile Safari/537.36

为了更直观的观察不同机型之间的差异,我选用了三种不同表现的机型放到一起做个对比。

| 机型 | weight600 | 回退weight |
|---|---|---|
| ROG | ❌ | 500 |
| P20 | ❌ | 700 |
| iPhone | ✅ | - |
解决方案
方案一: 问题机型黑名单 ❌
维护一个有问题机型的列表,当useragent匹配到,就手动将weight 600强制回退到weight 700。这是最容易想到的方案,并且代码逻辑简单。难点是如何收集到所有有问题的机型,我用云真机测了很多机型,发现有问题的机型在手机品牌、系统版本、浏览器内核版本都没有明显的聚合特点,所以收集这个黑名单不太可能实现。
方案二:对比文字宽度 ❌
对于同一段文字,如果font weight大的占的宽度更宽,就可以通过计算容器的width来判断两个font weight渲染是符一致。但实测后发现,不管font weight多少,同样的文字总是占据同样的宽度,所以这个方案也不可行。
方案三:统一用font-weight: bold ❌
网上也有提到统一用bold来加粗的方案。[CSDN传送门]
但经实测,font weight bold和600在视觉上并不一致,从W3C的规范上来看bold对应的值是700,所以在支持weight 600的机型上,bold要更粗一些,仍然与设计稿不符,这个方案也不可行。

方案四:黑点检测 ❓❓❓
这个问题似乎在技术层面无解了,难道只能与设计同学沟通,让设计接受统一使用700或bold这条路吗?秉着技术不应该成为业务瓶颈的信念,我开始从零重新思考这个问题,我开始聚焦在两个核心问题上:
- 字重的本质是什么?
- 设计同学是如何发现字重与设计不符的?
字重更大 -> 文字更粗 -> 文字颜色区域更大,而设计师也是通过观察,看到了文字颜色占据的区域不同,而不是通过某些计算发现的。所以这两个问题之间是有关联的,于是我突然奇想,既然字重是通过图像作用于人的视觉,能否用技术去模拟设计师识别字重的方式去解决这个问题?
图像在计算机中本质就是像素点的数据,对于单个像素点有多种不同的存储格式,比较常见有RGBA,就是用4个0~255之间的数值分别表示Red-红色,Green-绿色,Blue-蓝色,Alpha-透明度,RGB每个值越大,代表这种颜色越深。
我把“中”这个字截图,放大很多倍后,可以看到每个方格就是一个像素点,黑灰色的像素点就组成了“中”字的形状。那通过计算黑灰点像素点的数量,就可以反向得到这样一个推导过程像素点数量越多 -> 文字颜色区域更大 -> 文字更粗 -> 字重更大。

计算黑点数
至此,核心问题就变成了计算图像中的黑点数,主要涉及下面四个环节,而第1、3点是技术核心。

文字图像化
H5页面上的文字属性DOM范畴,而我们的目标是图像,而canvas就是连通DOM与图像的桥梁。看看canvas能否满足文字图像化的需求。
fillText方法,用来绘制文本字符。[canvas fillText传送门]font属性,用来指定绘制文字时所使用的字体样式。 [canvas font传送门]
通过调用上面两个api,就可以实现将指定样式的文本绘制到canvas中。
获取像素数据
获取图像像素数据也有对应的api。
CanvasRenderingContext2D: getImageData() => ImageDataImageData.data: Uint8ClampedArray
描述了一个一维数组,包含以 RGBA 顺序的数据,数据使用 0 至 255(包含)的整数表示。
就是说每一个像素在数组中占了4个元素,分别存储了R、G、B、A的值。比如下图,有红黄蓝三个像素点,对应的ImageData.data值为
[
255, 0, 0, 255, // red
0, 255, 0, 255, // green
0, 0, 255, 255, // blue
]

识别有效像素
再回到这张图上,目标是要识别组成文字的像素,直观的看就是黑色和灰色,但文字的边缘灰色程度会有不同,如果要枚举出所有的灰色就太低效了。我们可以从相反的角度来思考,只要不是白色就是有效像素,这样就只用识别一种颜色(255, 255, 255, x)就可以了。
部分示例代码
const MAX_COLOR_VALUE = 255;
function isBlackPoints(red: number, green: number, blue: number): boolean {
return (
red !== MAX_COLOR_VALUE
|| green !== MAX_COLOR_VALUE
|| blue !== MAX_COLOR_VALUE
);
}
统计有效像素
这一步是最简单的,遍历图像中的所有像素,对有效像素计数即可。
部分示例代码
function calcBlackPoints(data: Uint8ClampedArray): number {
let blackPoints = 0;
const data = context.getImageData(0, 0, width, height).data;
for (let i = 0, len < data.length; i < len; i += 4) {
if (isBlackPoints(data[i], data[i + 1], data[i + 2])) {
blackPoints += 1;
}
}
}
判断font weight渲染是否一致
最后要判断两个font weight渲染是否一致,只需要对比两个图像的有效像素点数量是否相同
部分示例代码
function isSameWeight(weight1: number, weight2: number): boolean {
return calcBlackPoints(getImageData(weight1)) - calcBlackPoints(getImageData(weight2)) === 0;
}
function getImageData(weight: number): Uint8ClampedArray {
// 省略实现代码
return context.getImageData(0, 0, width, height).data;
}
更多思考
上面的方案虽然已经可以解决问题,但仍存在一些不足。
- 虽然对于文字渲染的场景,可以把颜色控制在黑、白、灰三类,但真实世界是由各种颜色组成的,如果有其他颜色加入,将会影响这个方案的通用性和准确率。
-
假定不是白色的区域就是有效像素,但实际上一些非常浅的灰色,肉眼也是几乎识别不出来的,这样从人的感观来看,其实并不算有效像素。下图从左到右色值依次是255 -> 250 -> 240 -> 230 -> 220 -> 210 -> 200,220之前在没有白色对比的情况下,肉眼是比较难分辨出来的,这样的颜色对文字粗细的影响其实可以忽略。

- 只要有效像素差1点就认为是不同字重,事实上少量的像素点差异不会影响人对文字粗细的感知,因此需要允许一定的误差范围。
优化
灰度化
对于第一个问题,如果有办法将彩色的图像变成黑白灰,就可以无缝与上面的方案对接。修图软件中有一个很常见的黑白或灰度滤镜,可以把照片变成只有黑、白、灰风格的,那这个滤镜是如何实现的呢?首先要了解几个概念。
灰度颜色
当一个RGB表示的颜色R=G=B时,这个颜色就叫做灰度颜色。
灰度值
当R=G=B时,R的这个值就叫做灰度值。一般计算灰度值有两种策略:
- 平均值法。
Gray = (R + G + B) / 3 -
加权平均法。
Gray = R * 0.299 + G * 0.587 + B * 0.114加权平均法的原理是,在人眼中,绿色变化对亮度的影响敏感度最高,红色其次,蓝色最低。科学们经过大量的实验,得出这三个加权系数。
由此可以得出计算灰度值的函数
function calcGrayscale(red: number, green: number, blue: number): number {
return red * 0.299 + green * 0.587 + blue * 0.114;
}
灰度化
把一张图的每个像素的RGB颜色替换成对应灰度颜色的处理就叫做灰度化。看代码更容易理解。
function grayscale(data: Uint8ClampedArray): Uint8ClampedArray {
const grayscaleData = new Uint8ClampedArray(data.length);
for (let i = 0, len = data.length; i < len; i += 4) {
const gray = calcGrayscale(data[i], data[i + 1], data[i + 2]);
grayscaleData[i] = grayscaleData[i + 1] = grayscaleData[i + 2] = gray;
grayscaleData[i + 3] = data[i + 3];
}
return grayscaleData;
}
我写了一个小的demo,展示了灰度化后的效果。[灰度化传送门]

二值化
对于第二个问题,我们期望能去掉一些肉眼不易觉察的点,保留那些在视觉上真正影响文字粗细的点。还是以这张灰度化的鹦鹉为例,如果想要得到鹦鹉的轮廓而忽略背景(背景并非纯白,只是较浅的灰色)。

我们设定一个灰度阈值,当图像上的灰度值小于等于这个值时,就变成纯黑色(0, 0, 0),如果大于这个值就变成纯白色(255, 255, 255),这样最终就得到一张只有纯黑和纯白色的图片,这种处理就叫二值化。
以下是维基百科对二值化的解释。[二值化]
二值化(英语:Binarization)是图像分割的一种最简单的方法。二值化可以把灰度图像转换成二值图像。把大于某个临界灰度值的像素灰度设为灰度极大值,把小于这个值的像素灰度设为灰度极小值,从而实现二值化。
下面的动画展示了在不同阈值下,对图像做二值化处理的结果。随着阈值的增大,会出现更多的黑点。[二值化传送门]
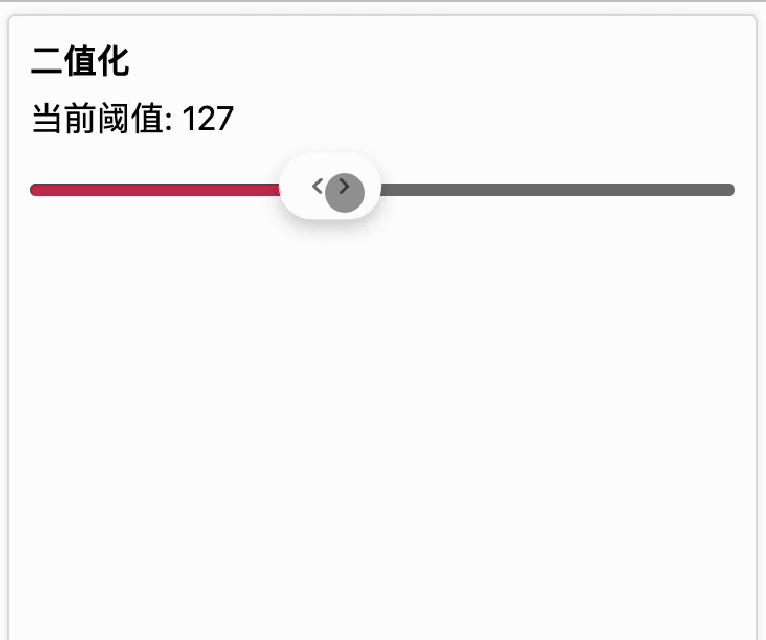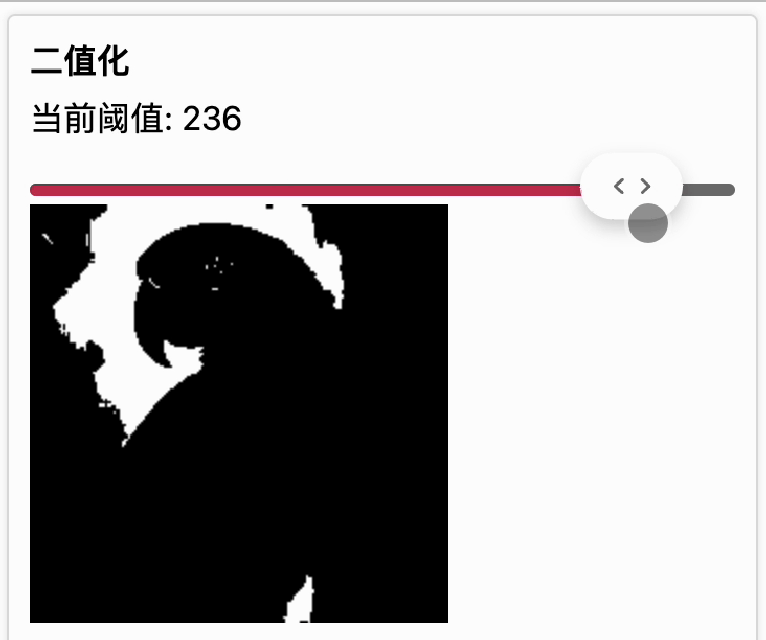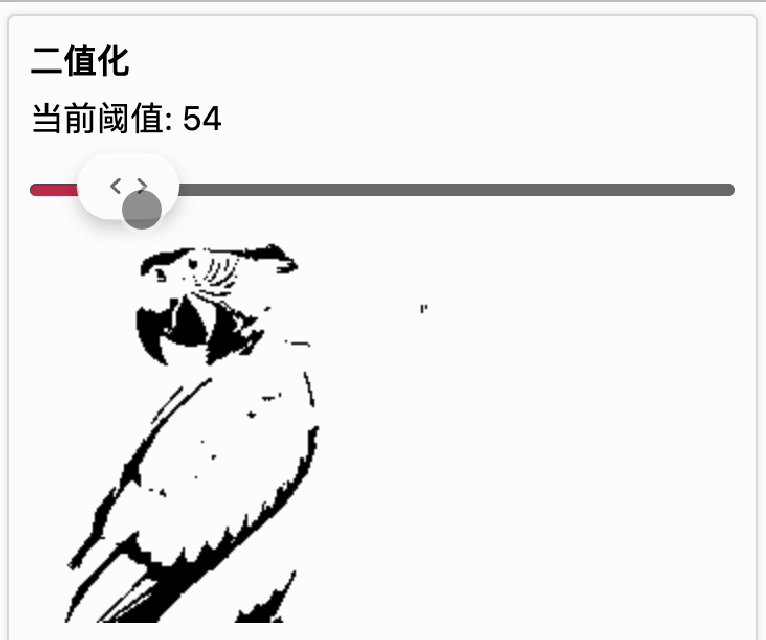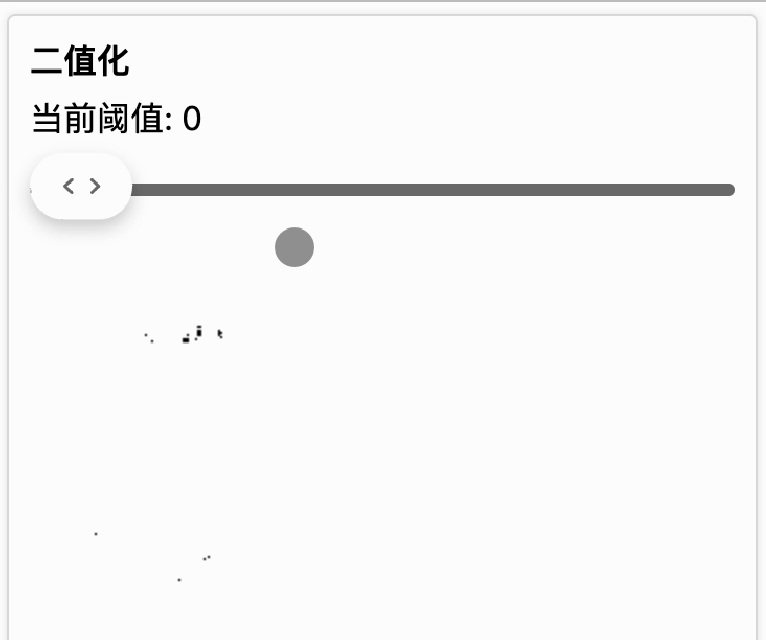
可以看到,对文字进行二值化后,文字边缘更清晰了。
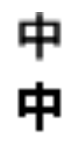
下面是将文字灰度化和二值化后,计算有效像素的综合示例。[传送门]
误差值
对于最后一个问题,要允许少量的误差,只需要多加一个参数即可。伪代码如下:
interface IOption {
/**
* 二值化阈值
*/
threshold?: number;
/**
* 允许误差范围,两个weight有效像素差在误差范围内,仍然返回true
*/
errorRange?: number;
}
function isSameWeight(weight1: number, weight2: number, { errorRange = 0, threshold }: IOptions = {}): boolean {
const blackPoints1 = calcBlackPoints(weight1, threshold);
const blackPoints2 = calcBlackPoints(weight1, threshold);
const diff = Math.abs(blackPoints1 - blackPoints2);
return diff <= errorRange;
}
最后,对于font weight问题的完整处理流程如下。

收获
- 对于一些复杂问题,当站在技术角度找不到突破口时,可以尝试回到问题的起点,脱离技术去思考问题的本质。这其实是第一性原理的应用。
- 从问题和技术两端思考,将大问题拆成小问题;对表层问题挖掘,去寻找本质问题。直到找到问题与手上已有技术的结合点,进而解决问题。