背景
最近花了不少时间在处理业务反馈的bug上,而在这些时间里,分析和修复往往只占20%不到,80%左右的时间花在了解重现场景,可以说非常低效。我最近刚好给vue官方提了一个bug issue[#10747]。对比之下,我发现很多开源组织,对于反馈bug都有一套标准流程,这些流程能让维护者专注在bug修复上。这也是为什么这些开源组织能在全球范围协同开发,并且保持高效响应的一个关键原因。
反观我目前遇到的痛点,接到反馈时只有很少的有效信息,像平台、系统版本、机型、浏览器UserAgent这些基本的信息也需要大量的沟通,才能从业务方获取到,这无疑让debug过程变得非常低效。
什么是低效的反馈
在说明如何高效反馈前,我想先通过实际的案例,来说明一下什么样的反馈是低效的。
案例一
Popup组件的z-index异常,请修复。
存在的问题
- 缺少意图描述(在什么场景下,想达到一个什么样的效果,我如何使用了Popup)。
- 没有描述问题的表现本身(即预期是什么,实际的表现是什么),而是在从技术的角度给了一个实现细节。
- 缺少重现环境信息(平台/系统版本/机型/UA等)。
- 缺少重现步骤。
案例二
华为P20和三星Note 9组件不渲染
- 截图。
- 解决组件不加载的问题。
存在的问题
- 缺少重现环境信息。
- “组件不加载”不是问题表现,是对问题表现的判断。
本质 —— 有效信息不足
通过上面的案例,不难发现大多低效的反馈都有几个特点,而这些特点从本质上都是有效信息不足。
- 一句话bug。—— “某某某功能有问题,麻烦看一下。”
- 缺少对意图的描述。(非常重要,技术人员的反馈往往会忽略这点)
- 缺少对问题表现的细节描述,把一些自己未经验证的判断,甚至是实现细节当成问题反馈。
- 缺少重现环境信息。
- 缺少最小化重现步骤。
什么是高效的反馈
我们先看一下目前几个比较火的开源项目的bug issue模板。
- Vue

- React
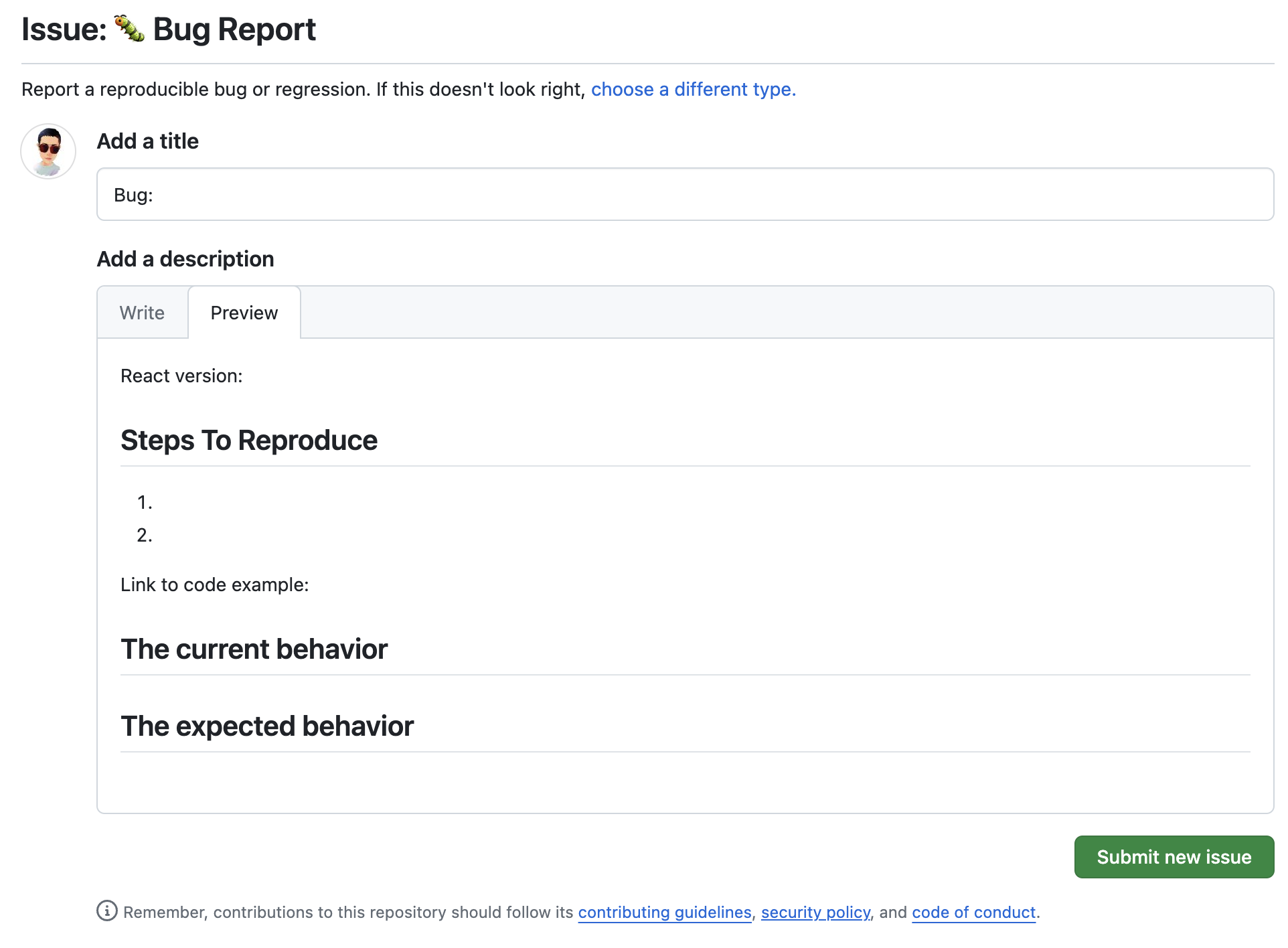
- VsCode

不难发现,这些大型开源项目的bug report模板不约同的都要求包含以下信息:
- 版本信息。
- 最小化重现步骤。
- 期望结果与实际结果。
- 重现demo代码。
- 其他补充说明。(截图、操作视频等)
最小化重现步骤
其中最重要的一条就是最小化重现步骤,Vue官方对最小化重现步骤做了详细的解释。
所谓『重现』,就是一段可以运行并展示一个 bug 如何发生的代码。
文字是不够的 如果你遇到一个问题,但是只提供了一些文字描述,我们是不可能修复这个 bug 的。首先,文字在描述技术问题时的表达难度和不精确性;其次,问题的真实原因有很多可能,它完全有可能是一个你根本没有提及的因素导致的。重现是唯一能够可靠地让我们理解问题本质的方式。
重现必须是可运行的 截图和视频不是重现。它们仅仅证明了 bug 的存在,但却不能提供关于 bug 是如何发生的信息。只有可运行的代码提供了完整的上下文,并让我们可以进行真正的 debug 而不是空想和猜测。当然,在提供的重现的前提下,视频或是 gif 动画可以帮助解释一些比较难用文字描述的交互行为。
重现应当尽量精简 有些用户会直接给我们一整个项目的代码,然后希望我们帮忙找出问题所在。此类请求我们通常不予接受 ,因为:
你对你的项目的代码结构可能已经非常熟悉,但我们并不是。阅读、运行、分析一个完全陌生的项目是极其耗费时间和精力的。
由于涉及了大量业务代码,问题可能是你的代码错误,而不是 Vue 的 bug 所导致的。
一个最小化的重现意味着它精确地定位了 bug 本身 - 它应当只包含能够触发 bug 的最少量的代码。你应当尽可能地剔除任何跟该 bug 无关的部分。
如何提供一个重现 除非你的 bug 只有在构建工具下才能重现,否则我们建议使用诸如 JSFiddle, JSBin 或是 Codepen 这样的在线代码服务来提供重现。如果你的 bug 必须用到构建工具,那么我们建议使用 vue-cli 来搭建一个新项目,推送到 GitHub 并提供仓库的链接。
为什么“最小化重现步骤”如此重要
Debug过程的本质
1. 定位bug
定位bug本质上是一个逻辑推导的过程。由于满足了C1、C2、C3这三个条件(重现条件),产生了R这个结果(Bug)。
2. 修复bug
修复bug本质上就是消除C1、C2、C3与R之间的因果关系。
重现步骤其实就是C1、C2、C3这些条件,它们是逻辑推导的输入参数,如果输入参数不足,就无法建立它们与结果的关联;输入参数过多,则会干扰真实条件与结果之间的必然联系,增加定位的难度;而这里面最坏的情况就是,错误的输入会推导出一个错误的结论。
因此最小化重现步骤是整个debug过程的基石。
如何找到最小化重现步骤
找重现步骤并不难,但难的是如何确定这些步骤是最小化重现步骤。要想了解如何找到最小化重现步骤,有必要先深入理解一下最小化重现步骤的本质是什么。
最小化重现步骤的本质
从逻辑学的角度来理解最小化重现步骤就是产生bug的充分必要条件。wiki上对充分必要条件的解释。
充分必要条件,简称充要条件,是逻辑学中用于描述两个陈述之间的条件关系或包含关系的术语。
在逻辑学中:
当命题“若P则Q”为真时,P称为Q的充分条件,Q称为P的必要条件。
因此:
当命题“若P则Q”与“若Q则P”皆为真时,P是Q的充分必要条件,同时,Q也是P的充分必要条件。
当命题“若P则Q”为真,而“若Q则P”为假时,我们称P是Q的充分不必要条件,Q是P的必要不充分条件,反之亦然。
上面的解释可能不够直观。换一个角度来描述: 充分必要条件就是,若P成立,则Q一定成立;若P不成立,则Q一定不成立。
举个例子:人类存活(P)和呼吸(Q)之间的关系。
用官方的定义理解
- 人类存活(P) -> 一定会呼吸(Q) —— 成立
- 可以呼吸(Q) -> 人类一定可以存活(P) —— 不成立(缺水、食物、伤病、意外也可能导致不存活)
用简化后的定义理解
- 人类存活(P) -> 一定会呼吸(Q) —— 成立
- 人类不存活(!P) -> 一定是因为无法呼吸(!Q) —— 不成立(缺水、食物、伤病、意外也可能导致不存活)
所以人类存活是呼吸的充分非必要条件。
用充分必要条件来理解最小化重现步骤就是,按这些步骤一定能重现bug(充分);而改变或去掉任意一个步骤,bug必定不能重现(必要)。
借助逻辑学上的定义,我们再回过头检视日常工作中,遇到的绝大多数bug反馈所提供的重现步骤是夹杂了干扰因素的充分条件,而非必要条件。
举个例子
理论可能不好理解,还是举个例子说明。前段时间处理了一个业务方反馈的使用组件库报错的bug。详情见[一行HTML注释引发的血案]。
最初的反馈提供的重现步骤是:
- 页面上使用输入框和数字键盘组件。
- 点击输入框,弹出数字键盘进行输入。
- 点回退按钮(单页面应用的路由回退)。
定位过程比较复杂,那篇文章已经做了详情说明,这里用一个中间步骤的结论来看一下这些步骤是什么条件。
- 页面上使用输入框和数字键盘组件。
- 使用输入框,但不指定type=”amount”,无法重现。说明是非充分条件。
- 不使用数字键盘也能重现,说明是非必要条件。
- 点击输入框,弹出数字键盘进行输入。
- 不使用数字键盘,仅点击输入框,也能重现。说明点击输入框是充分条件(无法确定是否必要)。
- 弹出数字键盘是既非充分也非必要条件。
- 点回退按钮(单页面应用的路由回退)。
- 使用v-if对组件进行销毁也能重现。说明路由回退是充分不必要条件。
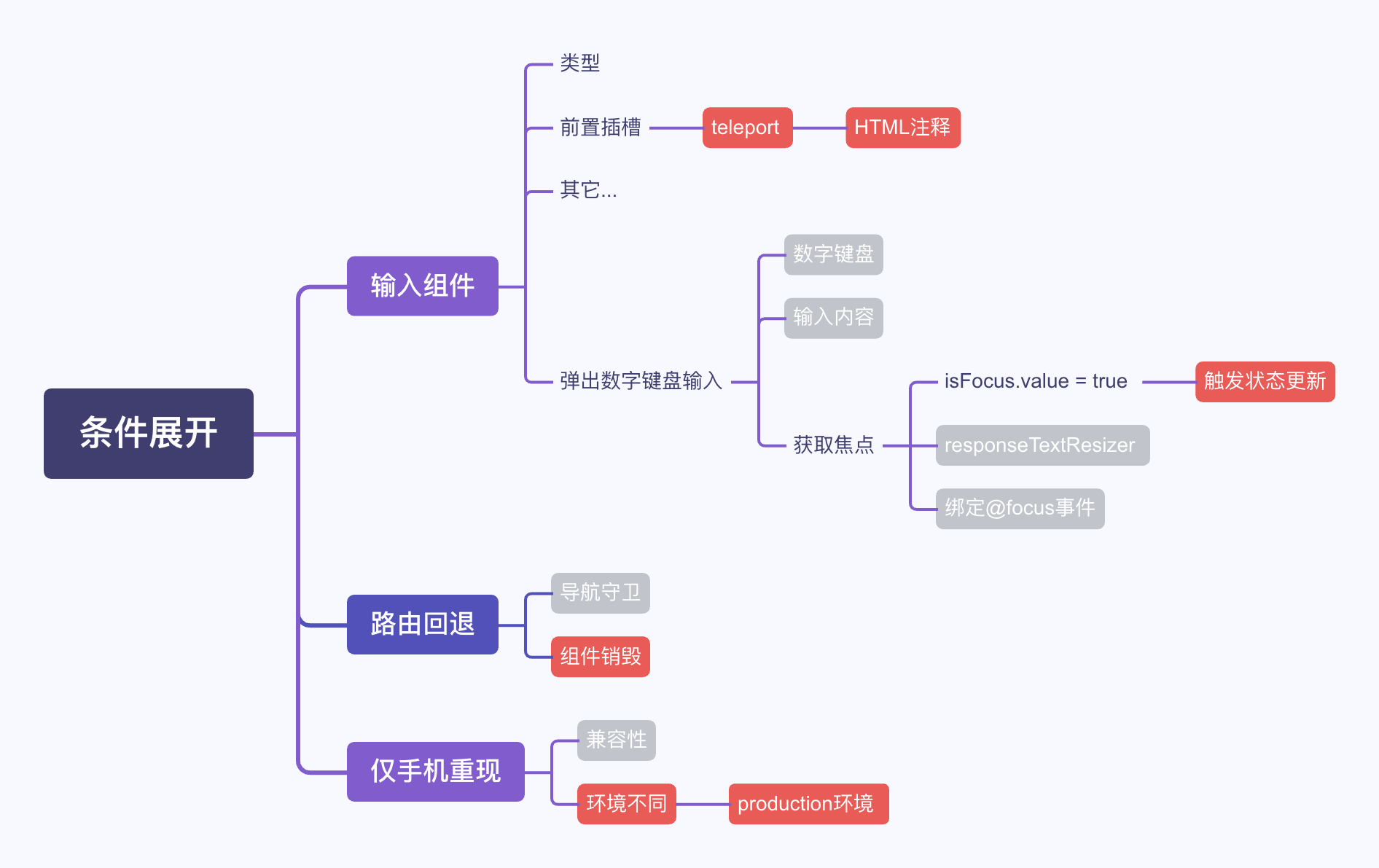
最后定位到是vue的bug,那就需要进一步排除组件库本身的代码的干扰,来看一下最终给vue官方提供的最小重现步骤是什么样的。
- 切换成production mode
- 在一个组件Comp中使用teleport,并在teleport的顶级节点中添加html注释
- 更改Comp组件中的任意一个状态,触发vue更新
- 销毁组件
验证这是否是最小重现步骤的方法,就是让其中任意一个步骤不成立,bug都无法重现。[演练场]
重新理解debug过程
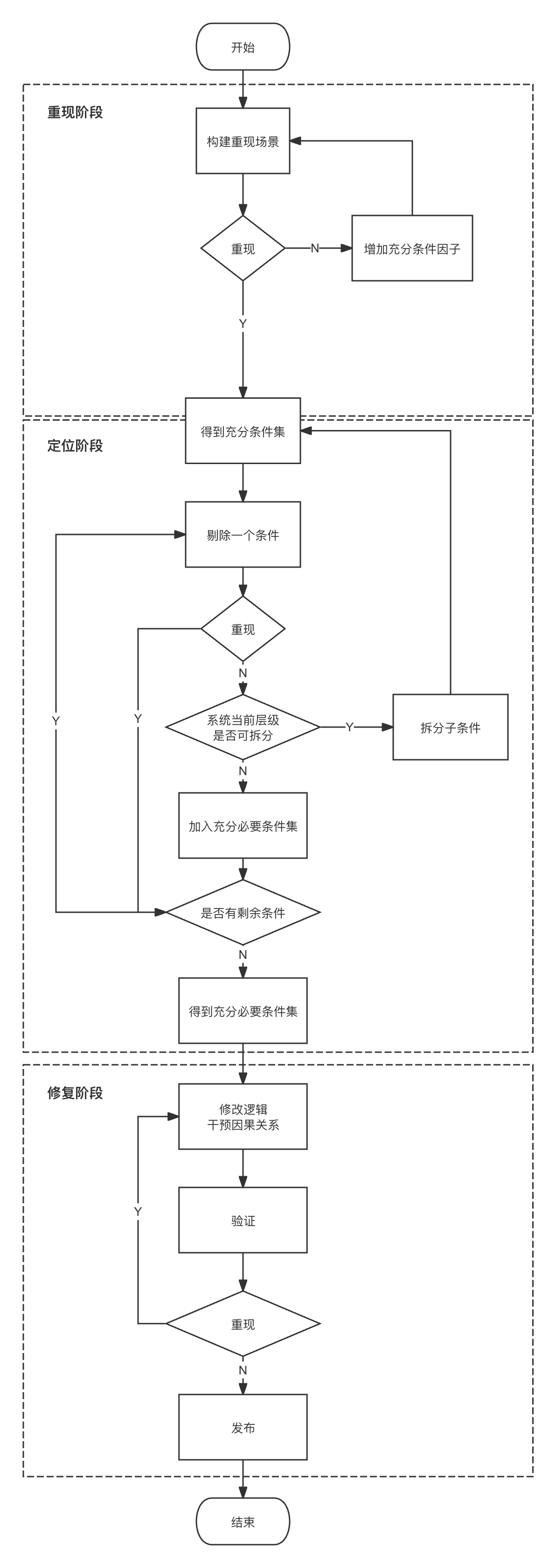
以前对于debug过程只是一个基于经验的模糊认识,这里从逻辑学的角度出发,重新理解一下debug的过程
重现阶段
如果无法重现,说明充分条件不具备,因此重现是一个不断往充分条件集里加入新的相关因子的过程(做加法)。
常见的手段有下面几种:
- 增加条件输入。
- 通过沟通从反馈方获取可能遗漏的细节。
- 分析现有条件。
- 通过推导、拆分、相关性扩散等方式,以现有条件为基础衍生出更多条件。
- 代码逻辑分析。
- 通过现有条件结合代码逻辑,将这些条件通过代码逻辑处理后,所能产生的结果,作为新的条件。
- 借助前人经验。
- 通过搜索、询问他人等方式,获得类似场景的信息。
当然这些手段不是独立存在的,大部分场景需要结合起来使用。
定位阶段
重现出来后,如果能够精确定位到产生bug的地方,说明这些条件满足或接近满足充分必要条件。如果还是难以定位,说明参杂了过多的非必要条件,因此定位是一个不断从充分条件集里剔除非必要条件因子的过程(做减法)。
剔除非必要因子主要方式就是做减法,但这里要注意的是,每一个条件的剔除都是个反复迭代的过程,因为一个条件可能包含了若干子因素,需要对每个子因素进行排查,直到自己代码所处的层级不可拆分为止。(还是用上面的例子说明,业务方能拆分的最小颗粒度就是组件,所以业务方反馈给组件库的是能够重现的特定组件,以及这个组件的属性值;而我反馈给vue时,就是仅使用原生DOM和vue内置组件重现的场景)
修复阶段
通过重现和定位,找出了充分必要条件和bug之间的因果关系,修复就是通过代码干预这个因果,使因果不再成立。
下面的流程图可以更直观的说明这个过程
再看看实战中是如何运用这一过程的
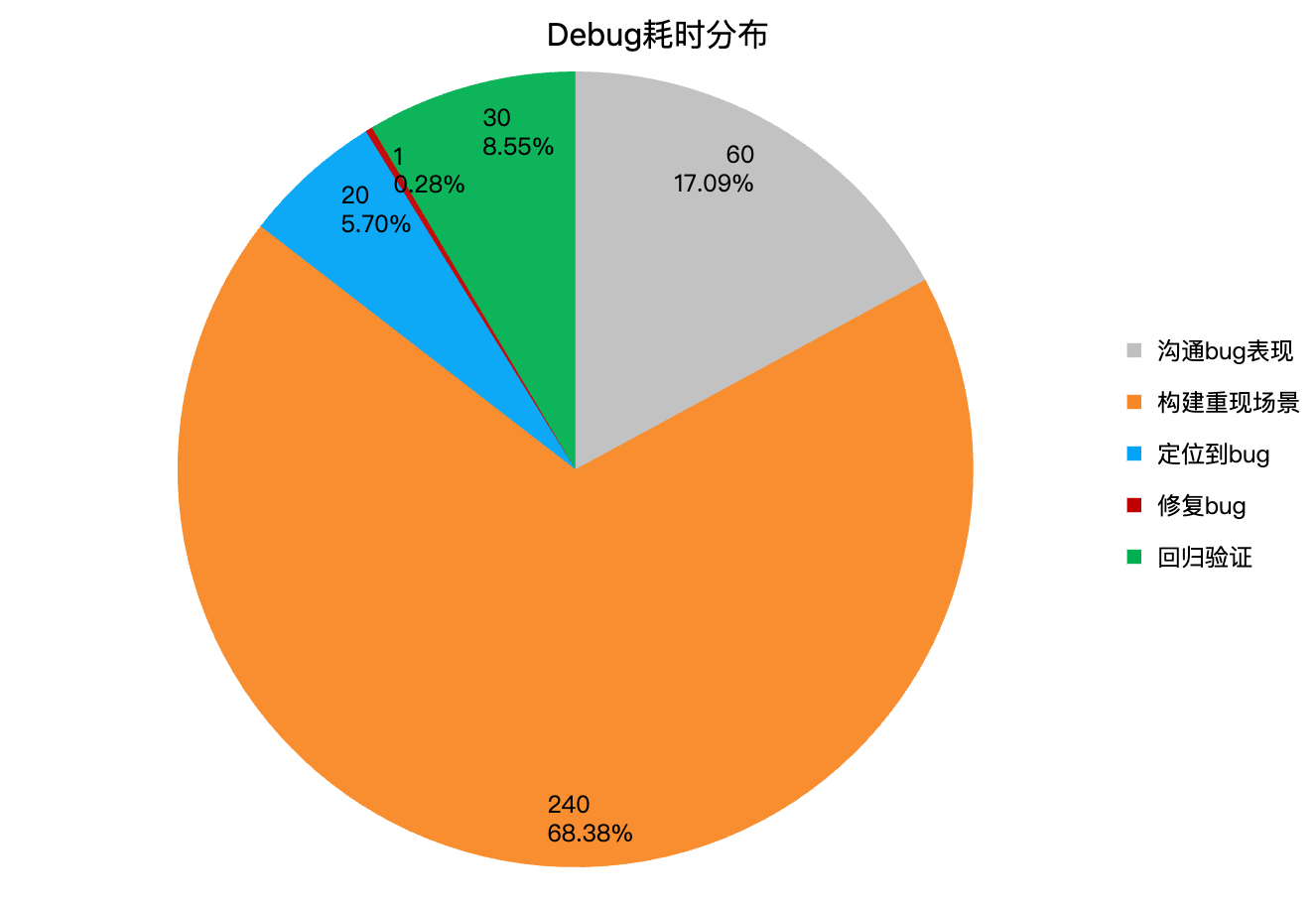
是否有必要
后面复盘了这个bug的处理过程,对各个环节的耗时分布进行统计,可以看到前期的沟通+重现bug占了大约85%的时间,而重现bug之后,找到bug原因和修复bug分别仅占了8.5%和0.28%,这个数据说明了在反馈bug前,如果能够提供最小重现步骤,将会大大提高解决bug的效率。
一般来说,当有bug需要反馈给其他人处理,是团队协作才有的场景。明明是B团队的bug,A团队是否需要花时间去提供最小重现步骤?我认为是有必要的,Vue官方对原因已经说明的非常清晰了。
我想补充一点,A团队在自己的项目中发现bug,引发bug的原因往往是复杂的,而A对自己的项目是最熟悉的,所以排除自己项目的干扰因素(非必要条件)是最高效的;如果bug产生于B团队的代码,B团队去修复bug也是最高效的。从整个项目的经济效益来看,这样分工与协作能使bug产生的负面成本降到最低。假设把分工反过来,由B团队去A团队项目中找最小重现步骤,再由A团队去修复B团队代码中的bug,将会是什么样的结果?
虽然看上去不管由谁做,都是构建最小重现步骤、定位bug、修复bug,这些事情并没有变多或变少,为什么分工不同会在效率和成本上会有如此大的差异?我认为主要是因为不合理的分工,中间会产生大量的学习成本、沟通成本这些隐性成本。几乎所有的团队协作都不是零和游戏,也许其中一方多承担了一点点,局部来看是吃亏的,但却让整体收益大大提升,最后自己反而得到了更高的收益。
或许从正面说不够有说明力,我们从反面看会是什么样的结果。
假设A团队不提供最小重现步骤
- B团队不予处理(开源项目的做法)。
- B团队按自己理解构建重现步骤,无法重现,放弃处理。
- B团队反复与A团队沟通细节,尝试自己构建重现步骤,双方均投入人力。
- 由于整个运行环境的差异,很难100%还原。最后有可能重现,也可能依旧无法重现。
前两种情况,bug未得到修复,A团队会承受bug所带来的负面影响。最后只能自己解决,除了自己提供最小重现步骤本来的工作量,还多出了深入到B团队项目中定位和修复,而由于对于B项目的不熟悉,必定会耗费大量的时间,但最后未必可以解决。
第三种情况,B团队由于不熟悉A团队的项目,又加上沟通本身的不精确性,最后即使能得到最小重现步骤,也是A、B两个团队人力的叠加,并且加上沟通过程增加的额外成本,最后也是未必可以重现。
不难看出这三种情况,都是在A团队独立提供最小重现步骤的成本之上,又增加了额外的成本,而结果还存在不确定性。由此可见,最高效、最经济的做法就是由A提供最小重现步骤,由B去修复问题。
科斯定理
诺贝尔经济学奖得主罗纳德·科斯提出了一个著名的理论,被称为[科斯定理]
只要财产权是明确的,并且交易成本为零或者很小,那么,无论在开始时将财产权赋予谁,市场均衡的最终结果都是有效率的,实现资源配置的帕累托最优。
原话比较晦涩难懂,科斯定理的核心是站在交易成本的角度来看待问题。我举一个生活中的例子。
追尾事故后车全责
不知道大家有没有想过,为什么在追尾故事中总是判定后车全责。如果从造成追尾的原因来定责,有可能是前车急刹导致追尾,这样应该是应该是前车的责任才对。其实这条法律在制定时就是依据了科斯定理,是从成本的角度考虑的。
- 首先,一旦追尾发生,双方都是受害者,换个角度说,如果能够避免追尾,那双方都是受益者,所以避免追尾是双方共同的目标。
- 其次,如果由前车避免追尾,那就需要时刻观察后车的情况,而人在开车时,正常是观察前方的,所以前车需要额外付出向后观察的成本,以及向后观察带来的风险成本(与前方相撞);而后车不管是不是为了避免追尾,都是在时刻观察前方的,所以即使加上避免追尾这一职责,既没有增加额外成本,也没有带来安全风险。因此对后车而言可以以更低的成本,达成双方共同的目标(避免追尾)。
所以这个场景用到的原则就是:
谁避免意外所付出的成本越低,谁的责任就越大。
依据科斯定理,也进一步说明了应该由A团队提供最小重现条件,可以使双方的利益最大化。