最近项目临近上线,项目组主要精力都放在修复bug上,做最后的冲刺。Bug处理多了,我有了两个小的感悟,和大家分享一下。
为什么定位bug比较痛苦
不知道大家有没有和我一样的感受,定位bug要比解决bug或实现新功能更痛苦。除了找不到引起bug的原因而产生的焦虑,还有一种更底层的不协调感,那种感觉就像是在看一个镜像文字。
很明显,这种不协调感不是工作压力带来的。我剖析了bug修复的整个过程后,觉得这或许是人的思维模式决定的。
定位与修复
Bug修复一般包含定位与修复两个阶段。对于大多数bug,定位要远比修复难,我认为主要有两个原因。
1. 顺序颠倒
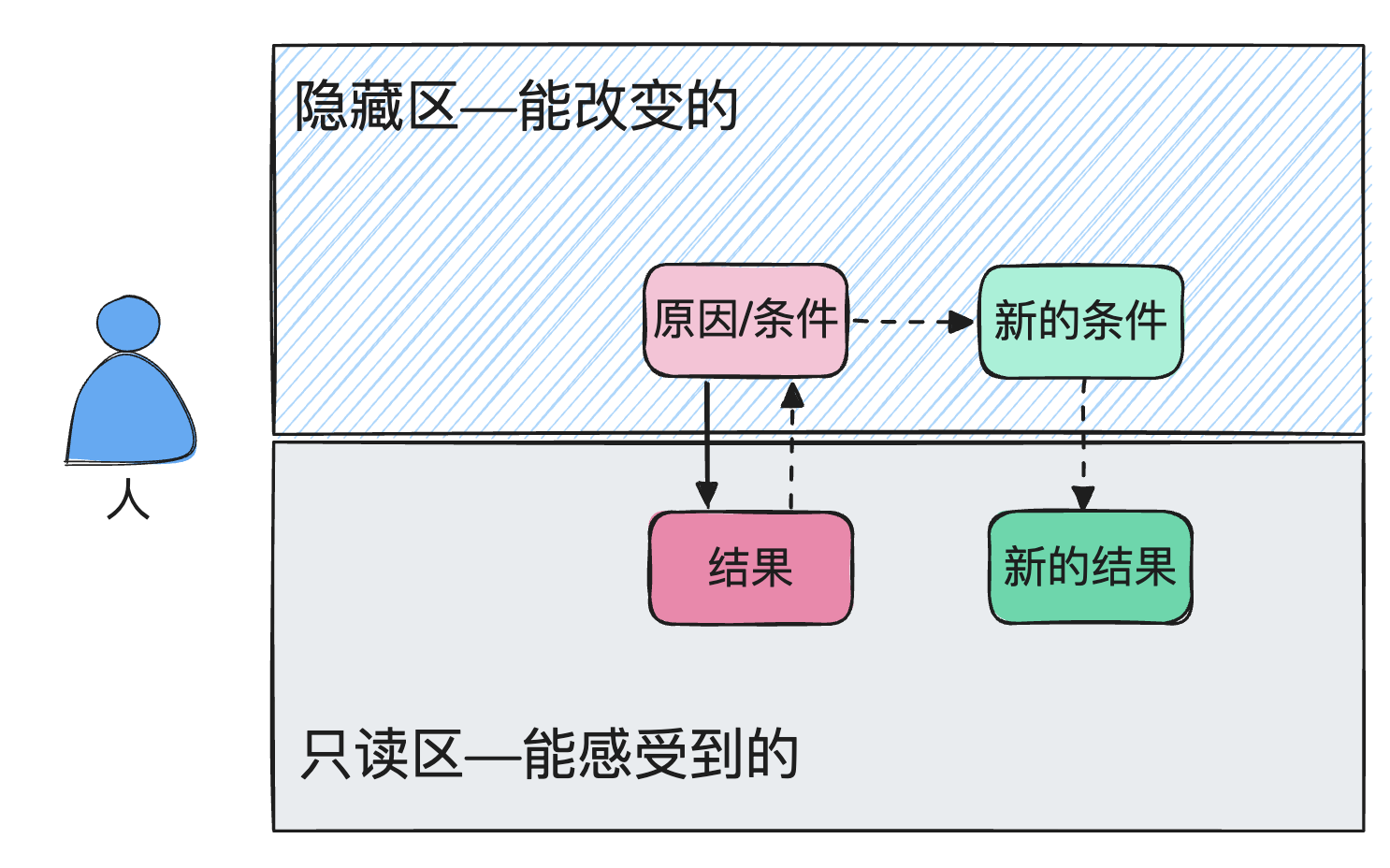
当接到bug,实际上是拿到了一个结果,而在我们的世界中,事件是按因 -> 果顺序发生的,我们无法直接修改结果,那是神才能做到的事,人类能做的是改变原因,进而影响结果。Bug定位的本质就是根据结果反推出原因,这个过程是与现实世界中事件发生顺序相反的,这种矛盾导致了不协调感。比如倒着读一句话,或者从后往前回忆一个过程都会有类似的感觉。
2. 过去时
除此之外,引发这个结果(bug)的原因是过去发生的,这个原因距发现结果的时间越长,反推就越困难,因为我们的大脑是顺着时间顺序接受信息的,检索过去的信息对大脑来说不是件容易的事。
修复
修复bug过程本质上是原因 -> 改变原因 -> 产生新的结果,这是一个因 -> 果顺序发生的过程,人不会产生那种不协调的感觉,所以大部分场景修复bug都是比较容易的。
整个过程如下图:
在哪个层级修复bug
分层设计普遍存在于软件开发中,在一些大型软件架构中,不同的层级由不同的人员、团队负责。有时触发bug与产生bug的不是同一个层级,甚至两者中间隔了多个层级,如果是比较底层产生的bug,处于两者之间的任意一层都有可能通过捕获和封装修复这个bug。
那么问题来了,如果大家都能修复,那应该由谁来修复呢?站在上帝视角看,当然是谁产生bug谁来修复,但实际情况往往更复杂,大部分bug的源头在最初没有人知道在哪一层,因为一个底层产生的bug,层层透传上去,可以认为每一层都是bug的生产方,对于触发bug的那层,它直接依赖的下层就是bug的生产方。工作中可能会遇到这种场景,大家互相推脱,认为不应该由自己处理,最后就由沟通比较弱势的团队处理。可是,这样真的合理吗?为了更清楚的解释这个问题,我结合之前定位的白屏bug,通过影响范围和修复成本两个方面来说明一下。
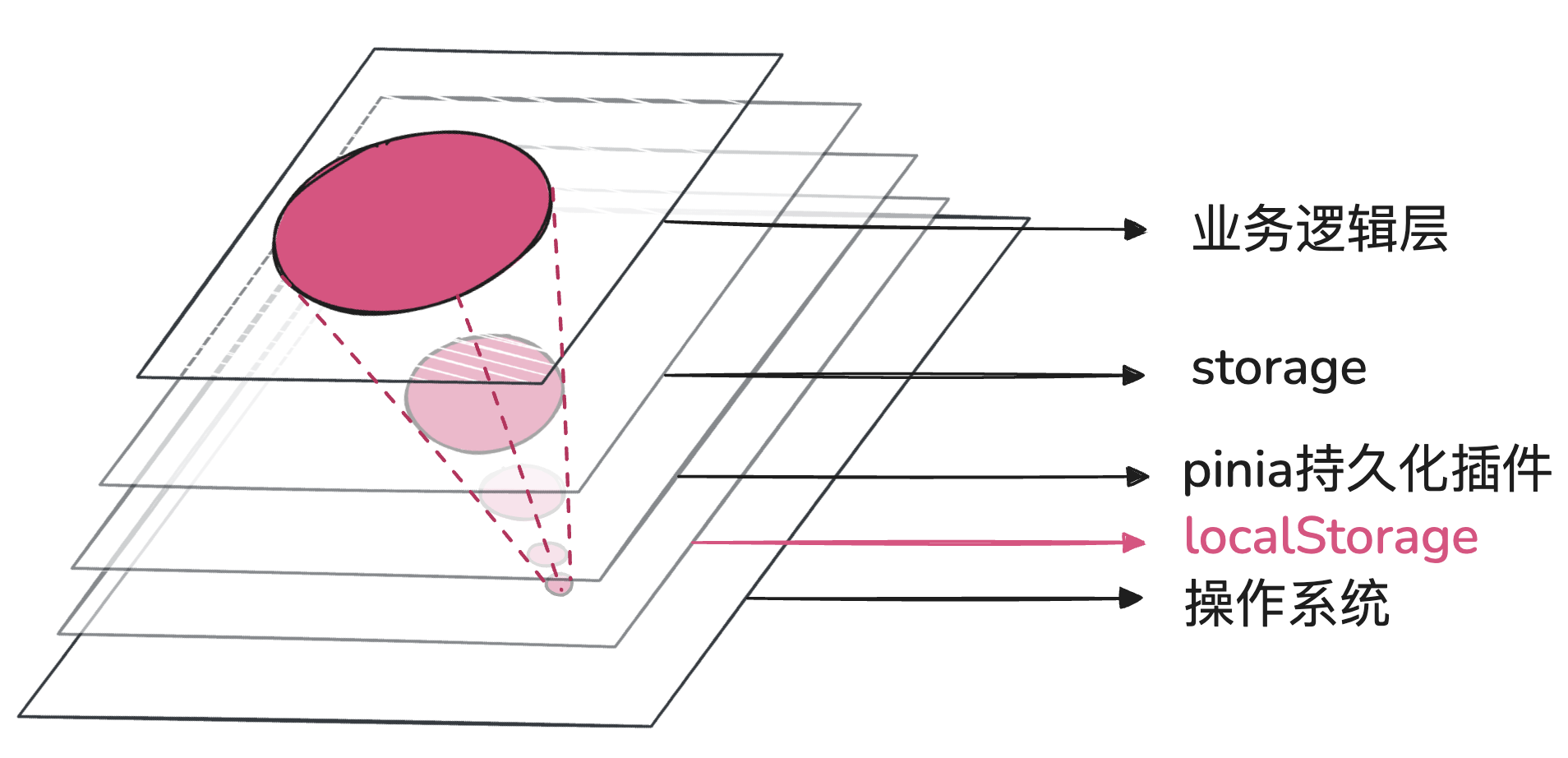
放射状影响
下图表示了当底层产生bug,向上透传的过程中,影响范围是呈放射状的。假设在操作系统层有一个api存在bug,localStorage中setItem和removeItem依赖这个api,这样在localStorage层,影响点就被扩散成两个api,如果是业务层,有10个模块调用了localStorage.setItem,影响点就是10个模块,这里可以得出两个结论。
- 越底层的bug,影响层数越多。
- 越往上层,受底层bug影响范围就越大。
前段时间微软的蓝屏bug,造成全球范围影响,就是因为是非常底层的操作系统bug。
修复成本
由于影响范围会呈放射状向上扩散,在离bug根源越远的层级就有越多的bug需要修复,但更可怕的是,上层不知道中间层级受这个根源影响产生了多少bug,这些bug对上层的影响可能还未被发现,就可能在未来造成巨大的损失。
如下图中,最底层的一个bug,如果想在第2层完全消除影响,需要修复2个bug;如果要在顶层消除影响,就需要发现并修复7个bug。更坏的一种情况,假设在第3层发现了红色的bug点,经排查是第2层红色的点引起的,第2层修复了此问题,第3层的红色bug点随之修复,在所有人都认为没问题的时候,实际上第3层还有3个灰色的bug点未被发现,而这些bug其实都是由最底层的一个bug点引起的,如果由最底层修复,上面所有层级不管是发现的,还是未被发现的bug都会被修复。
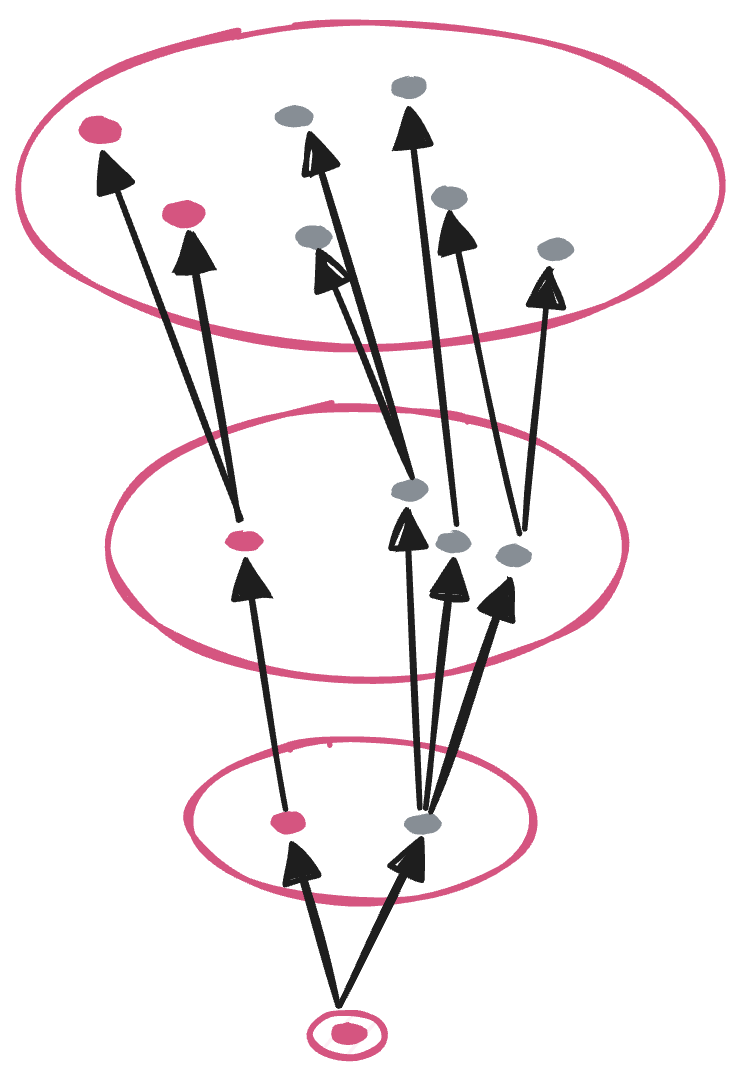
最佳修复位置
通过上图不难看出,理论上在bug根源处修复,成本最低,影响面最小。但实际上,有一些层级是无法干预的。比如白屏的例子,问题发生在webview层的localStorage,但我们无法修改webview的api,最后是在业务的storage层,把localStorage替换成了appStorage来解决。
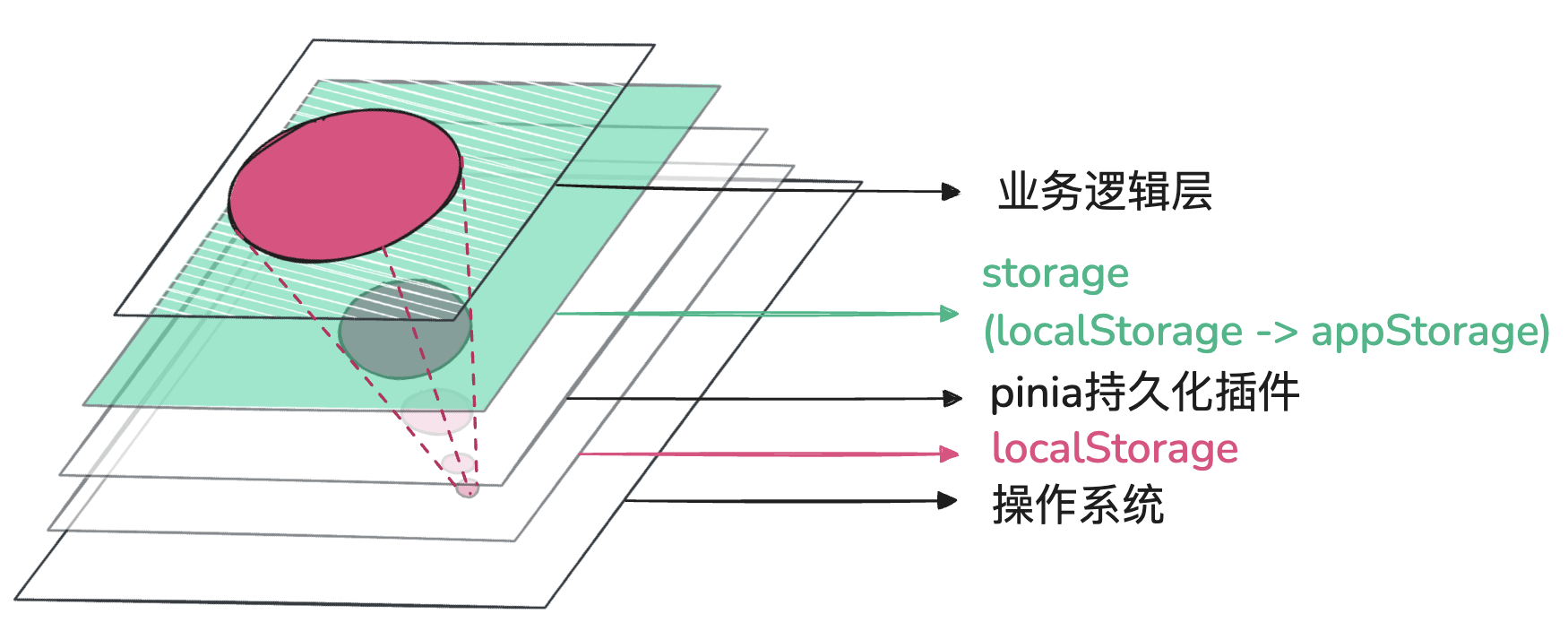
如果用一句话来总结,就是在能干预的层级中,尽量临近问题根源所在的层级修复。 当所有层级都遵循这个原则,就不需要把修复责任推给沟通弱势的团队。要做到这点,找到问题的根源就是重中之重,这也是为什么我对于bug,一定要追本溯源的原因。在不知道根源的情况下,通过盲目的修改,使bug暂时无法复现,这样做就好像是找到了一条绕开“坑”的捷径,但谁又能保证,这条捷径的终点会不会还是那个坑。